DOM_API
DOM_API
我们写HTML时会先写一个文档头<!Doctype html> 然后html head body
1 | <!Doctype html> |
head/body是可以省略的,这其实就是一棵树
这是我们大脑中对html的理解,而不是内存中的理解
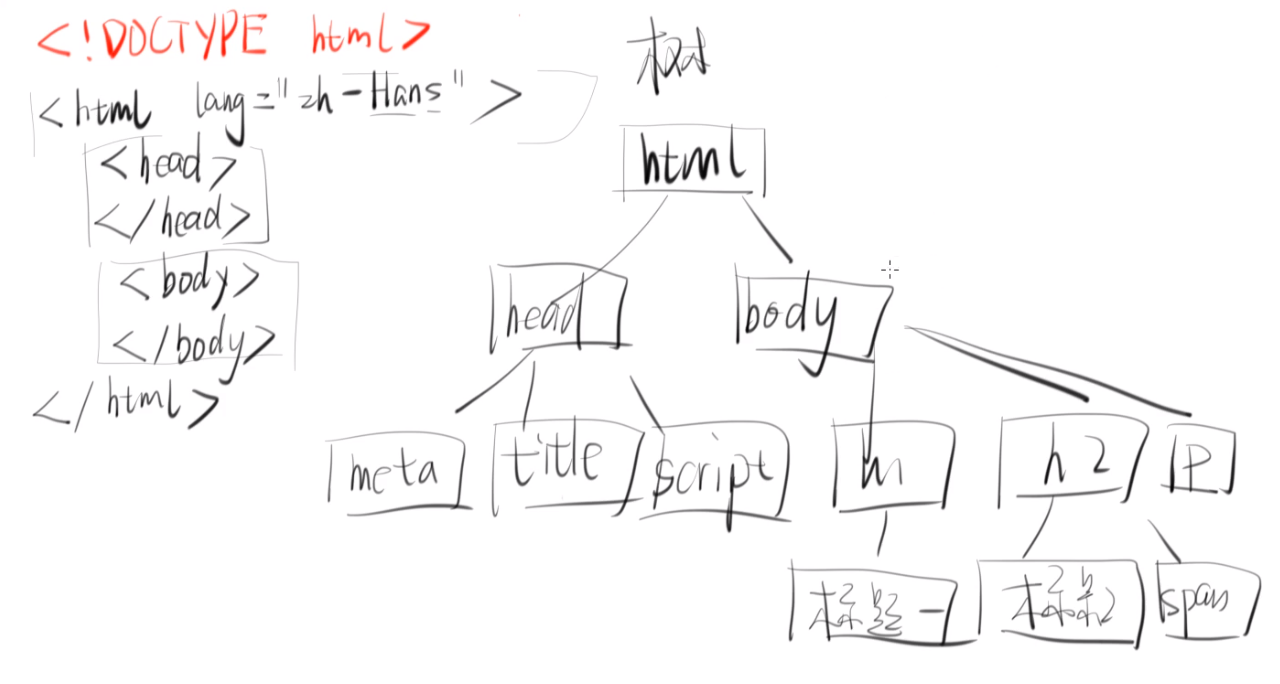
内存里是DOM(Document Object Model)文档对象模型
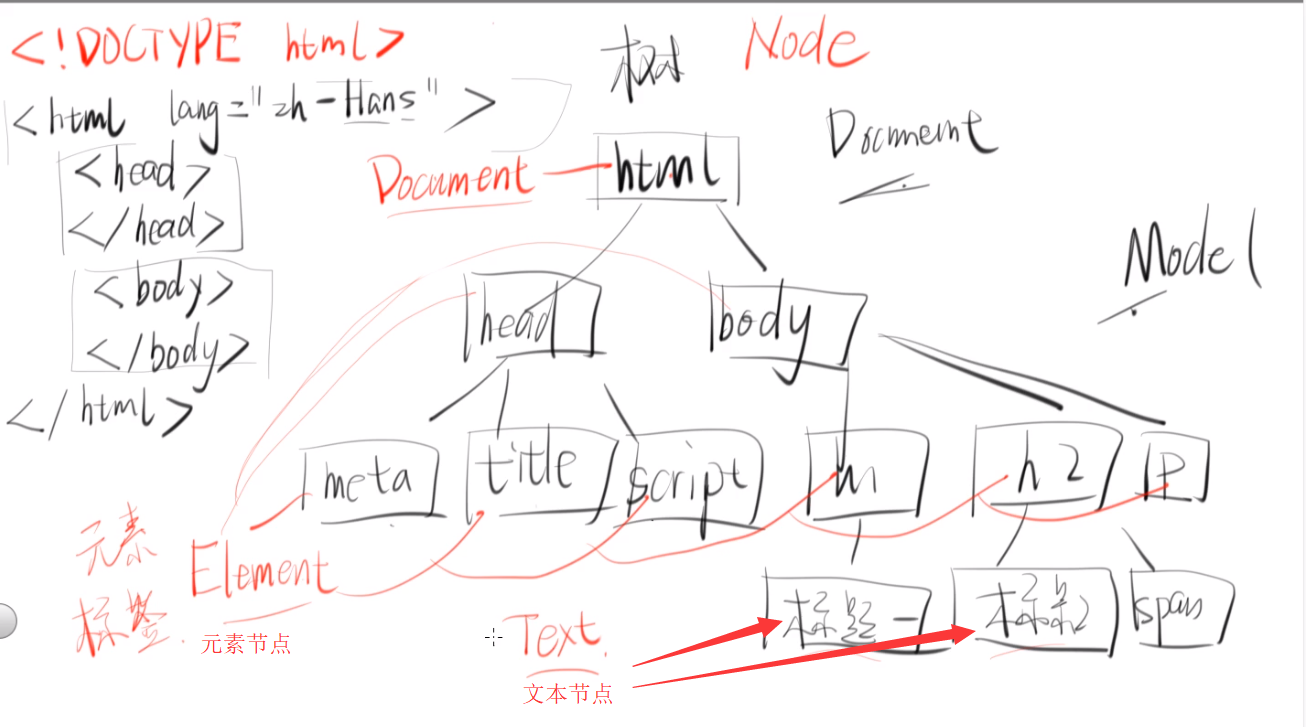
- 页面上所有标签都有跟它对应的构造函数
- 浏览器只要看到一个标签就会给给它构造出来一个对应的内存中的对象
- 页面中的节点通过(构造函数)==> 对象
这就是DOM api 如果你想操作一个节点就可以操作这个对象对应的api
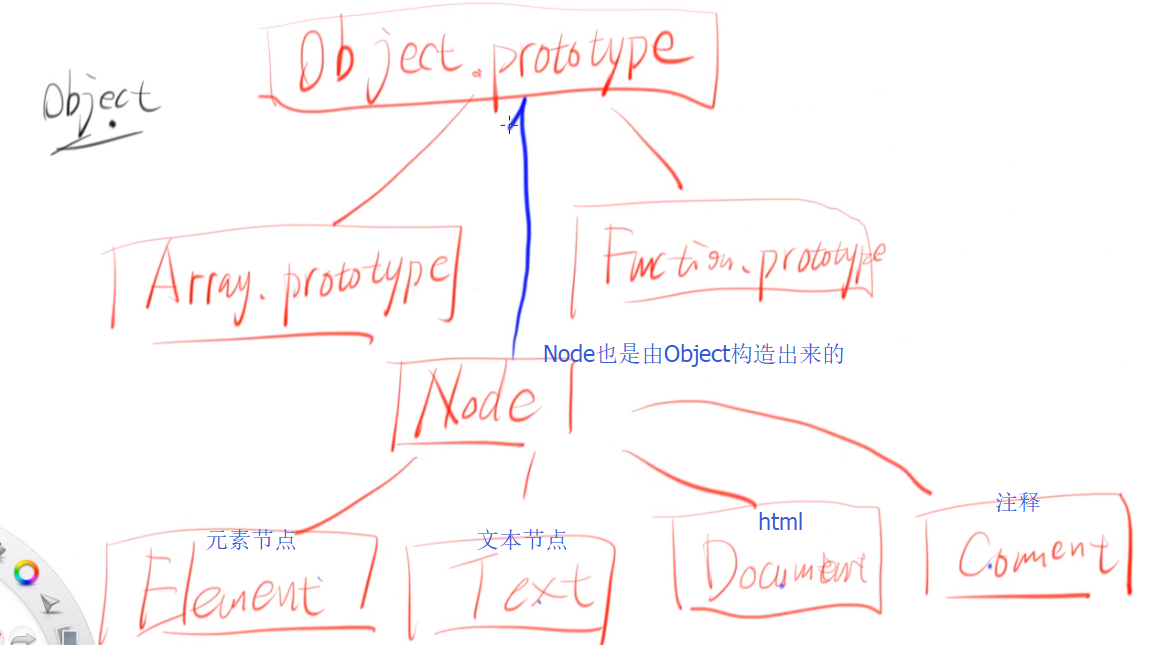
Node接口
1.属性
childNodes,firstChild,innerText,lastChild,nextSibling,nodeName,nodeType,nodeValue,outerText,ownerDocument,parentElement,parentNode,previousSibling,textContent
- document // document
- document.documentElement //html
- document.body // 代表body
childNodes && children
如果是节点是包含回车的
1 | document.body.childNodes //获取body下所有子节点 (注意子节点不是子元素,回车也是文本节点) |
firstChild/lastChild && firstElementChild lastElementChild
1 | document.body.firstChild //body的第一个子节点 注意是子节点 回车也是文本节点 |
previousSibling nextSibling && previousElementSibling nextElementSibling
1 | //兄弟节点 与 兄弟元素 |
nodeName
只有svg元素 返回的是小写”svg” 其他标签返回的都是大写
nodeType
- 返回节点的节点类型 是数值(为啥是数值,因为以前的内存紧张 节省内存 8M是豪华配置 )
- 1代表元素节点
- 3代表文本节点
- 除了这个 1、3它还存了一个常量 用来表示节点类型 Node.ELEMENT_NODE >
自行MDN
- 1 元素节点
- 3 文本节点
- 7
- 8 注释节点
- 9 Document节点
- 11 DocumentFragment 节点
innerText && textContent
在IE发明innerText之前 前端想要获取htmk代码的文本需要这样写
1 | <div> |
于是IE发明了 innerText 你爱用不用我自己觉得很爽
FF说了 你IE又搞特殊 于是FF出了个 textContent
innerText && textContent区别
- textContent 会获取所有元素的内容,包括 script 和 style 元素,然而 innerText 不会。
- innerText意识到样式,并且不会返回隐藏元素的文本,而textContent会。
- 由于 innerText 受 CSS 样式的影响,它会触发重排(reflow),但textContent 不会。
- 与 textContent 不同的是, 在 Internet Explorer (对于小于等于 IE11 的版本) 中对 innerText 进行修改, 不仅会移除当前元素的子节点,而且还会永久性地破坏所有后代文本节点(所以不可能再次将节点再次插入到任何其他元素或同一元素中)。
到底用谁
1 | 'textContent' in document.body ? document.body.textContent : document.body.innerText |
2.方法(如果一个属性是函数,那么这个属性就也叫做方法;换言之,方法是函数属性)
- createElement() //创建节点
- appendChild()
- cloneNode() //复制一个节点 有一个参数[param] true/false 默认false true代表深拷贝
- contains() //Node.contains()返回的是一个布尔值,来表示传入的节点是否为该节点的后代节点。
- hasChildNodes() //判断一个节点是否有后代节点
- insertBefore()
- isEqualNode() //节点是否相等 div2 = div1.cloneNode(true); div2.isEqualNode(div1) 返回true
- isSameNode() //判断是否相同(就是是不是同一个) 你与你自己肯定是同一个人 1===1
- removeChild() //移除一个节点,但是这个节点不是真的没了,还在内存里 只是从页面移除了
- replaceChild() //替换一个节点,但是这个节点不是真的没了,还在内存里 只是从页面移除了
- normalize() // 常规化
1 | var wrapper = document.createElement("div"); |
搞清楚英文单词的意思就知道用法
如果发现知道英文后依然不明白用法,看 MDN 的例子即可,如 normalize
DOM APi 无外乎「增删改查」
Document 接口
属性
- anchors //废弃 详情mdn 返回a标签 集合
- body
- characterSet //返回字符集
- childElementCount //返回元素个数
- children //返回子元素 伪数组
- doctype //返回文档头
- documentElement //返回页面根元素 html
- domain //返回域名
- fullscreen
- head
- hidden
- images
- links
- location
- onxxxxxxxxx //监听事件
- origin
- plugins //安装的插件 静态集合
- readyState
- referrer //你访问一个网址 浏览器会问你的引荐者是谁 不然就会被拒之门外
- scripts
- scrollingElement
- styleSheets
- title
- visibilityState
方法:
- close()
- createDocumentFragment()
- createElement()
- createTextNode()
- execCommand()
- exitFullscreen()
- getElementById()
- getElementsByClassName()
- getElementsByName()
- getElementsByTagName()
- getSelection()
- hasFocus()
- open()
- querySelector()
- querySelectorAll()
- registerElement()
- write()
- writeln()
考点
- previousSibling nextSibling
- innerText 和 textContent 的区别
- nodeType 1代表元素节点 3代表文本节点
- cloneNode() 设置参数可以深拷贝
- isEqualNode isSameNode 的区别 isEqualNode是两个节点是否一个样 isSameNode 是 是否是同一个
- normalize() 主要体现mdn的作用